I have been toying around with an idea of replacing the ObjectBuilder in the WCSF with a proper dependency injector. The Unity seemed like the obvious choice (someone even tried porting WCSF to Unity) so I have been reading Dependency Injection with Unity.
During my research I have stumbled upon the ugly side of the Unity: It can’t detect circular dependencies. I though that it is only true in some old version, it would be hell trying to find the circular dependency only with StackOverflowException so I tested it out. After all “One good test is worth a thousand expert opinions”:
public interface IA {}
public interface IB {}
public class A : IA
{
public A(IB ib) {}
}
public class B : IB
{
public B(IA ia) {}
}
[TestMethod]
public void UnityContainer()
{
using (var container = new UnityContainer())
{
container.RegisterType<IA, A>();
container.RegisterType<IB, B>();
container.Resolve<IA>();
}
}
It crashed, hard. The test didn’t pass, nor fail. I just got
—— Run test started ——
The active Test Run was aborted because the execution process exited unexpectedly. To investigate further, enable local crash dumps either at the machine level or for process vstest.executionengine.x86.exe. Go to more details: http://go.microsoft.com/fwlink/?linkid=232477
========== Run test finished: 0 run (0:00:05,2708735) ==========
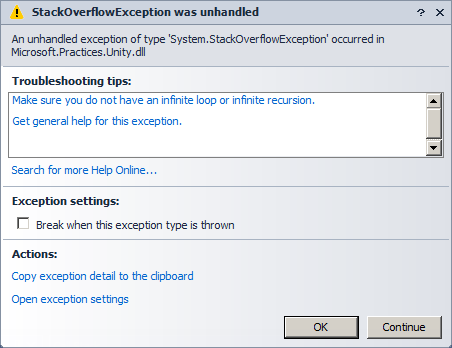 During debugging the test, I got the dreaded StackOverflowException, so there it is: No detection of circular dependencies in the Unity and that is the reason why I won’t be using it. There are other fishes in the barrel.
During debugging the test, I got the dreaded StackOverflowException, so there it is: No detection of circular dependencies in the Unity and that is the reason why I won’t be using it. There are other fishes in the barrel.
I have tried Ninject and Castle Windsor, thankfully, both detect circular dependencies and throw exceptions with meaningful messages. Ninject has this error message:
Ninject.ActivationException: Error activating IA using binding from IA to A
A cyclical dependency was detected between the constructors of two services.
Activation path:
3) Injection of dependency IA into parameter ia of constructor of type B
2) Injection of dependency IB into parameter ib of constructor of type A
1) Request for IASuggestions:
1) Ensure that you have not declared a dependency for IA on any implementations of the service.
2) Consider combining the services into a single one to remove the cycle.
3) Use property injection instead of constructor injection, and implement IInitializable
if you need initialization logic to be run after property values have been injected.
While Castle exception has this message:
Castle.MicroKernel.CircularDependencyException: Dependency cycle has been detected when trying to resolve component ‘UnityTest.A’.
The resolution tree that resulted in the cycle is the following:
Component ‘UnityTest.A’ resolved as dependency of
component ‘UnityTest.B’ resolved as dependency of
component ‘UnityTest.A’ which is the root component being resolved.
I am not impressed with the simplicity of the Castle nor with documentation of the Ninject, but I don’t want a nightmare of circular dependencies without meaningful error message in my project.

